


Foundations First: Four Pillars Every Enterprise Needs Before AI
Twenty years of building data platforms teaches you something that nobody puts in the AI hype cycle: the algorithm is the easy part.
I have spent my career on the layer underneath. The data pipelines, system architecture, and governance infrastructure connect raw enterprise data to the models that eventually use it. It is unglamorous work compared to training a model or fine-tuning a transformer. But it is the work that decides whether AI actually makes it to production or quietly stalls in a staging environment somewhere.
In December 2025, I gave a talk on “What Needs To Be In Place Before AI” for the IEEE Richmond Computer Society, you can find here YouTube, and the response told me this is something a lot of people are wrestling with. So here is the written version: four things that need to be in place before you touch a model, drawn from real systems and real failures.
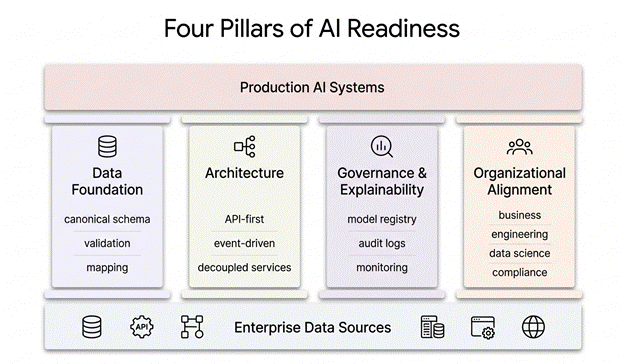
Figure 1: Four Pillars of AI Readiness
KEY TAKEAWAYS
● Why most enterprise AI pilots stall and what the real culprit is
● The four foundational pillars that determine whether AI succeeds or fails in production
● A concrete example from a real-world insurance quoting platform
● A practical checklist for architects, engineers, and technical leaders
● A simple test for when AI is the right tool and when it is not
Most Enterprise AI Pilots Do Not Deliver, Here Is Why
The numbers are not pretty. Only a small fraction of enterprise generative AI pilots ever produce measurable business impact. Most never make it past proof of concept. In regulated industries like insurance, only a handful of organizations have genuinely scaled AI across their operations. Everyone else is running pilots. The same pilots, sometimes, over and over.
We have already seen this pattern in claims automation. When automated systems are used without enough explainability and governance, an organization may move faster, but it may not be able to defend the decision later. That is where AI stops being an efficiency tool and starts becoming a risk. The frustrating part is that the models themselves are not necessarily broken. Often, the infrastructure around them was not there.
That is the version of AI failure that nobody talks about enough. It is not the dramatic, obvious kind. It is the slow, structural kind that builds up quietly until something forces it into the open.
The Four Ways I See AI Projects Fall Apart
These are not theoretical. I have watched each of these play out in real systems.
Data Is A Mess, And Nobody Wants To Deal With It
Data lives in silos. Teams have their definitions, their own formats, and their own timestamp conventions. When you train a model on that kind of fragmented input, you are not teaching it anything useful. You are asking it to make sense of contradictory signals. It learns to reconcile noise instead of recognizing patterns. And then you wonder why the predictions feel off.
Architecture Was Never Built To Support AI
AI gets bolted onto systems that were designed in a different era for a different purpose: monolithic, batch-oriented. No clean way to deploy a model, no way to monitor it once it is running, no safe path for updates. The team builds something that works brilliantly in isolation and has absolutely no route to production. So it sits in the lab, forever.
Nobody Can Explain What The Model Is Doing
Decisions get made, but the trail goes cold. There is no documentation available regarding the input data, the version of the model used, or the reasons behind its output. When a regulator asks, or a customer pushes back, or something goes wrong in a way that needs investigating, the organization has nothing. The AI system stops being useful and starts being a liability.
AI Team and The Business Are Not Talking to Each Other
The model gets built for a problem nobody in the business cares about. Or the business cares about the problem but does not trust the model and refuses to use it. Or it ships, and then nobody owns it afterward, and six months later performance has degraded quietly, and the first anyone notices is an unhappy customer or a metric that suddenly looks strange.
What the Inside of a Real Platform Looks Like
I should give you something concrete to anchor your thinking.
Consider a car insurance quote comparison website. You put in your details, and you get back a list of prices within a few seconds. Simple on the surface. Underneath it, the complexity is significant: dozens to hundreds of carrier integrations, millions of API transactions per year, hard real-time latency requirements, and a regulatory environment that means every decision has to be understandable and state-compliant. Here is the flow behind that interface:
Step 1: Customer data entry – Applicant fills in personal and vehicle details
Step 2: Rule engine filtering – Required fields validated, basic business rules applied
Step 3: API normalization – Requests standardized for the quoting engine
Step 4: Quote engine validation – State-specific coverages and rules applied
Step 5: Parallel carrier requests – Multiple carriers called simultaneously via API
Step 6: Carrier underwriting – Each carrier runs its own logic and returns a quote
Step 7: Quote aggregation – Responses stitched together, filtered, and adjusted
Step 8: Markup logic – Business-specific adjustments applied
Step 9: Best options display – Most relevant results surfaced to the customer
Data gets created and transformed at every step. If it’s not consistent, validated, and traceable at each handoff, then any AI you add will fail. And this is not an insurance-specific problem. Any complex enterprise platform has the same challenge. The industry changes, but the underlying issue does not.
Pillar 1: Sort Out Your Data First
The messiest part of any enterprise AI project is not picking the model. It is getting the data into a state where the model can actually learn something useful from it.
In systems I have worked on, different carriers would describe the same thing in entirely different ways. One sends the premium as an annual figure. Another sends it monthly. A third bakes fees into the total; a fourth lists them separately. Coverage labels are all over the place. “Liability,” “bodily injury,” and “third-party” can all mean the same thing depending on which carrier you are talking to. Timestamps come in whatever time zone and format that carrier happens to use.
You dump all of that into a model, but it does not learn patterns. It’s trying to make sense of incompatible inputs. The predictions will appear plausible until they no longer do. What actually resolves this problem:
● Canonical Schema: One data model that everything maps to. Premium is always expressed the same way. Coverage types use standard codes. Timestamps are normalized to UTC. Every source conforms to this model before it touches anything downstream.
● Documented Mapping Layer: For every source, you write down explicitly how their fields map to your schema and what transformations happen in between. This feels like overhead right up until something goes wrong at an inconvenient hour and you need to trace exactly where a number came from.
● Validation at Ingestion: If a source sends something that does not make sense, a negative premium, or an unknown coverage code, you catch it immediately. You log it, you alert someone, and you stop it from moving further into the system. You do not shrug it off, store it, and hope the model figures it out.
Pillar 2: The Architecture Has to Be Built for This
Many organizations realize too late that their current infrastructure was never designed to support their AI initiatives. Layering a real-time, adaptive system on top of batch-oriented monoliths does not work. The architecture presents challenges at every step. Part of what I do is design the platforms AI actually runs on. The ones that hold up in production tend to share a few characteristics:
● API-First Integration: Core systems expose versioned APIs rather than requiring direct database access. AI services plug in through well-defined interfaces and can be updated independently without touching everything else.
● Event-Driven Pipelines: Event streams like Kafka or Pulsar feed feature stores and monitoring systems in near-real time. This is what lets the system react to live data instead of always working from a stale batch.
● Decoupled AI Services: Models are deployed as independent services. You can update one, roll it back, or run an A/B test without redeploying the entire application. This matters more than it sounds when you are trying to hotfix something at 11pm.
● Observability Built in From the Start: Logs, metrics, and traces across the data pipelines and the AI services. Not added later. Build them in from the beginning. You cannot fix what you cannot see.
● Safe Deployment Patterns: Canary releases, blue-green deployments, feature flags. Every AI service should have a fallback to rules-based logic if something starts behaving unexpectedly.
Pillar 3: You Need to Be Able to Explain What the Model Did
This one matters in regulated industries for obvious reasons, but it matters everywhere else too, and I think many teams underestimate that until they are in trouble.
If your AI is making thousands of decisions a day, you need to be able to answer these questions at any point:
● What data went into this particular decision?
● Which version of the model produced this output?
● Why did this claim get flagged, or this quote come out the way it did?
● Are we watching for drift and bias over time?
The way you build toward that:
● Model Registry and Versioning: Every model tracked, along with its training data and deployment history. If a decision from six months ago gets challenged, you need to be able to reproduce what the model saw and what it decided.
● Feature Documentation: Not just “we used a credit score.” Which credit score, from which source, was processed, how, and on which date? The detail matters.
● Decision Logging: Inputs, outputs, and relevant metadata, captured for every AI-assisted decision. This is your audit trail.
● Regular Audits That Go Beyond Accuracy: Accuracy can look fine while bias builds up quietly underneath. Check for stability, fairness, and compliance on a schedule, not just when something forces you to.
Pillar 4: The Humans Have to Be Aligned
You can get the data right, build a proper architecture, put governance in place, and still fail. I have seen it. If the people and teams around the AI are not aligned, the whole thing falls apart regardless of how good the technical foundations are.
The pattern I see most often: a data science team builds something impressive without enough input from the business. The business does not understand it, does not trust it, and does not use it. If the model ships and nobody takes ownership of maintaining it, performance drifts over the following months, and the first anyone notices is a customer complaint or a metric that nobody can explain.
What works instead is treating the process as a shared project with clear ownership across every function:
● Product and Business own the problem definition, the success metrics, and the customer context.
● Engineering owns deployment, safety, and what happens in production.
● Data Science owns model performance, retraining, and fairness testing.
● Compliance and Risk own the regulatory and ethical questions.
● Finance owns the ROI thresholds and the criteria for stopping.
When You Should Not Use AI
This is the part nobody puts in the brochure.
Some of the best AI decisions I have been involved in were the ones where we decided not to build anything. Sometimes the problem just does not need a model. Here is roughly how I think about it:
Do not use AI when:
● A query or a rules engine gets you there just as well.
● You do not have enough data to learn anything reliable from.
● You cannot explain or defend the output to a regulator or a customer.
● The decision is high stakes and hard to reverse.
Use AI when:
● The volume is high enough that manual decisions do not scale.
● The patterns are genuinely too complex for rules to capture.
● You have clear metrics and can measure whether it is working.
● Mistakes are recoverable and the cost of being wrong is manageable.
● The four pillars are already in place.
Foundations First; Models Second
Here is what I have seen over and over across large-scale systems: the algorithm is maybe 20 to 25 percent of the work. The rest is data engineering, platform engineering, governance, and getting people aligned. Most organizations spend their energy on the 20 percent and wonder why nothing ships.
The ones that get it right invest in the foundation before they think about the model. Standardized data. Architecture that was built to support AI, not just tolerate it. Governance that lets you explain what happened and catch problems early. Teams that are working together instead of throwing things over the wall at each other. Get those four things in place, and the model almost takes care of itself. Skip one, and you will feel it eventually. Usually, it happens when you least expect it.
Foundations first. Models second. Everything else follows from that.
About Author
Malar Kondappan is a lead system architect with over 20 years of experience in insurance technology, cloud architecture, and large-scale data integration. She builds the data foundations and platform infrastructure that AI systems depend on, the layer between raw enterprise data and the models that use it. Her work sits at the intersection of system design, data engineering, and production-grade platform architecture. Connect with her on LinkedIn or watch her IEEE Richmond Computer Society talk on YouTube.
Meta Description: Most enterprise AI projects don’t fail because of bad models. They fail because of weak foundations. Malar Kondappan, a lead system architect with 20+ years in insurance technology and cloud platforms, breaks down the four pillars every organization needs for successful AI adoption.
Tags: AI, Architecture, Data Engineering, Enterprise, Best Practices